
Promotion planning software
Drive revenue, profit, and traffic with optimized promotion planning
RELEX promotion planning software helps drive revenue, profit, and online/offline traffic. Identify which campaigns to start, stop, and adjust, then determine which combination of price, tactics, and features will generate the best results for your business.
Drive higher sales, profit, and traffic
15%
profit improvement on promoted items
30%
sales uplift on promoted items
8 hours
saved per person per week on promotion management

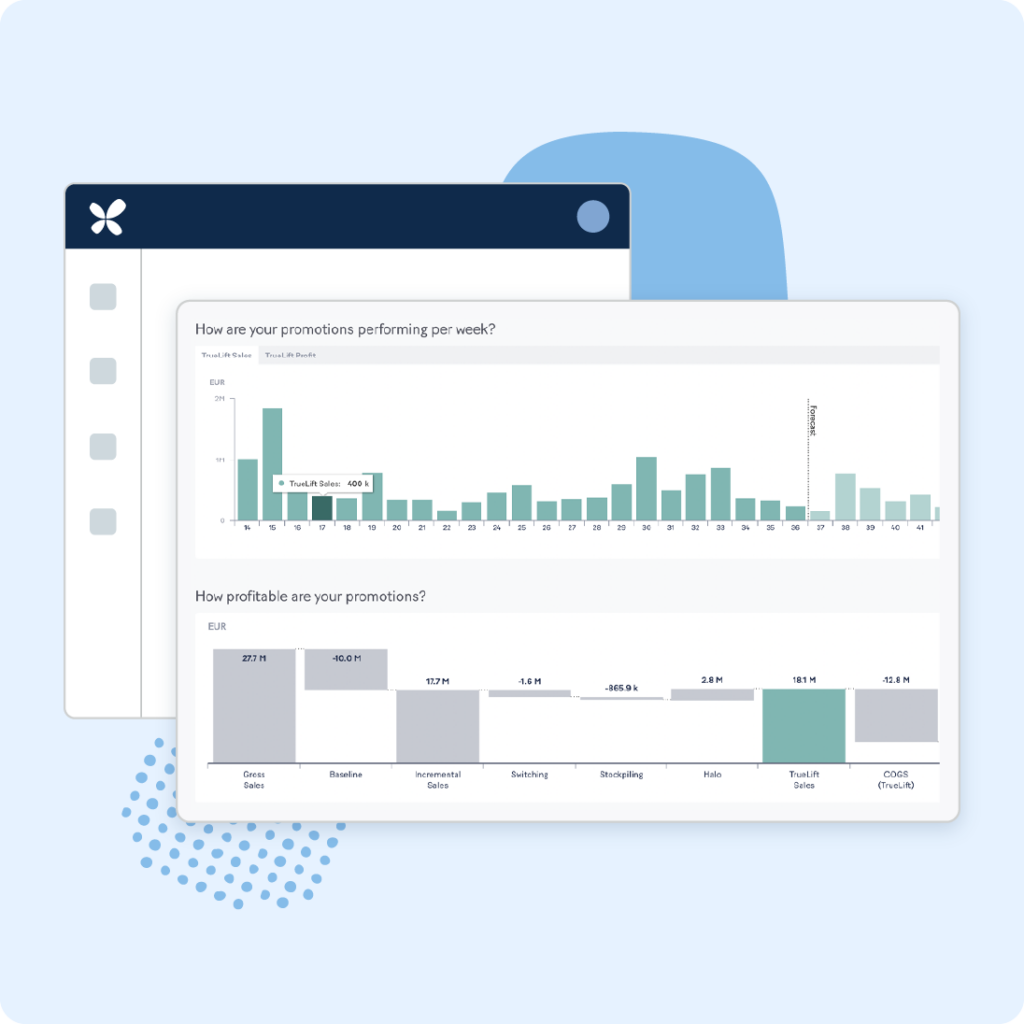
RELEX helps retailers plan, analyze, and optimize promotion campaigns
Use RELEX promotion planning software to create campaigns that drive higher sales and profit and create more predictable promotion performance.
Key features
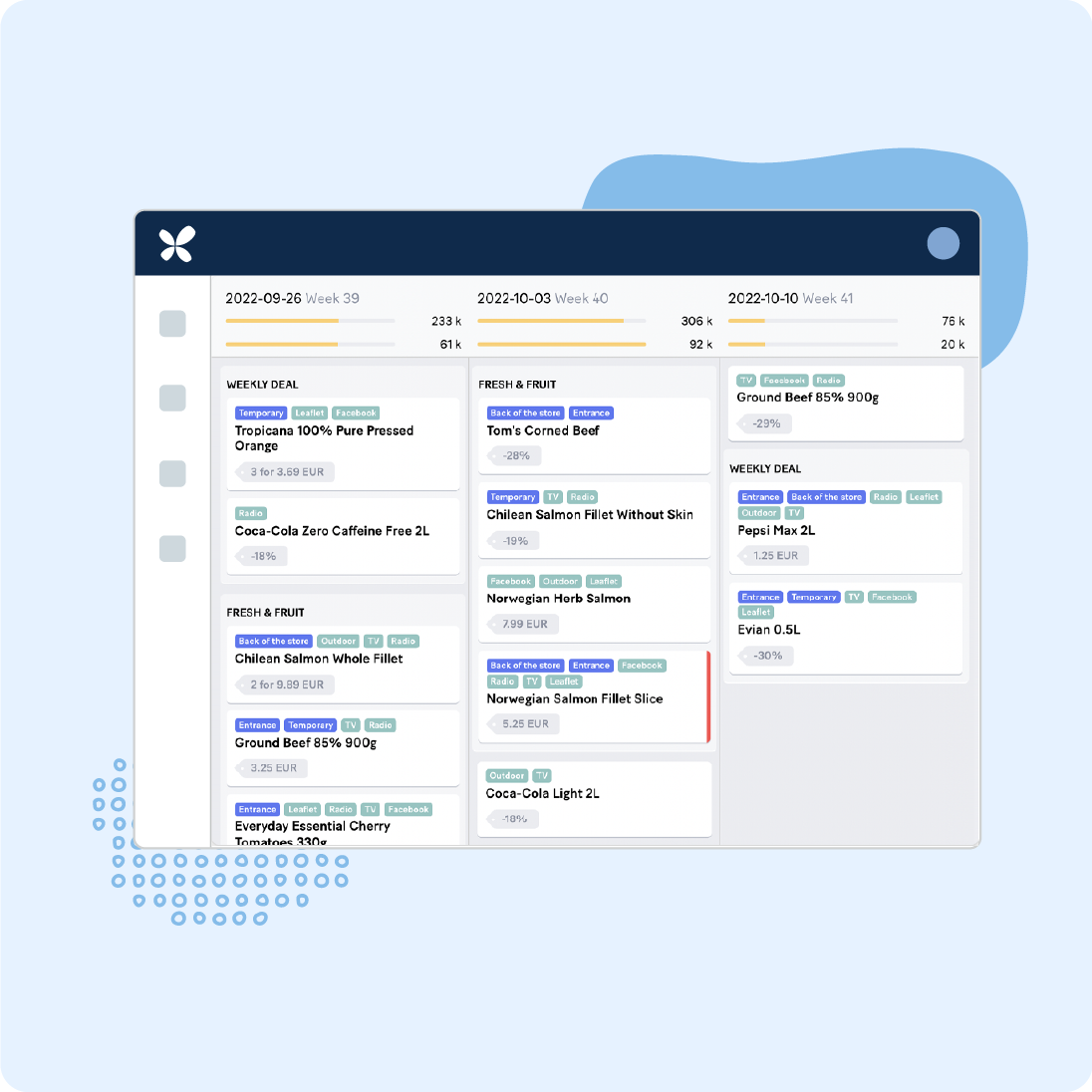
Plan, analyze, and execute optimized campaigns
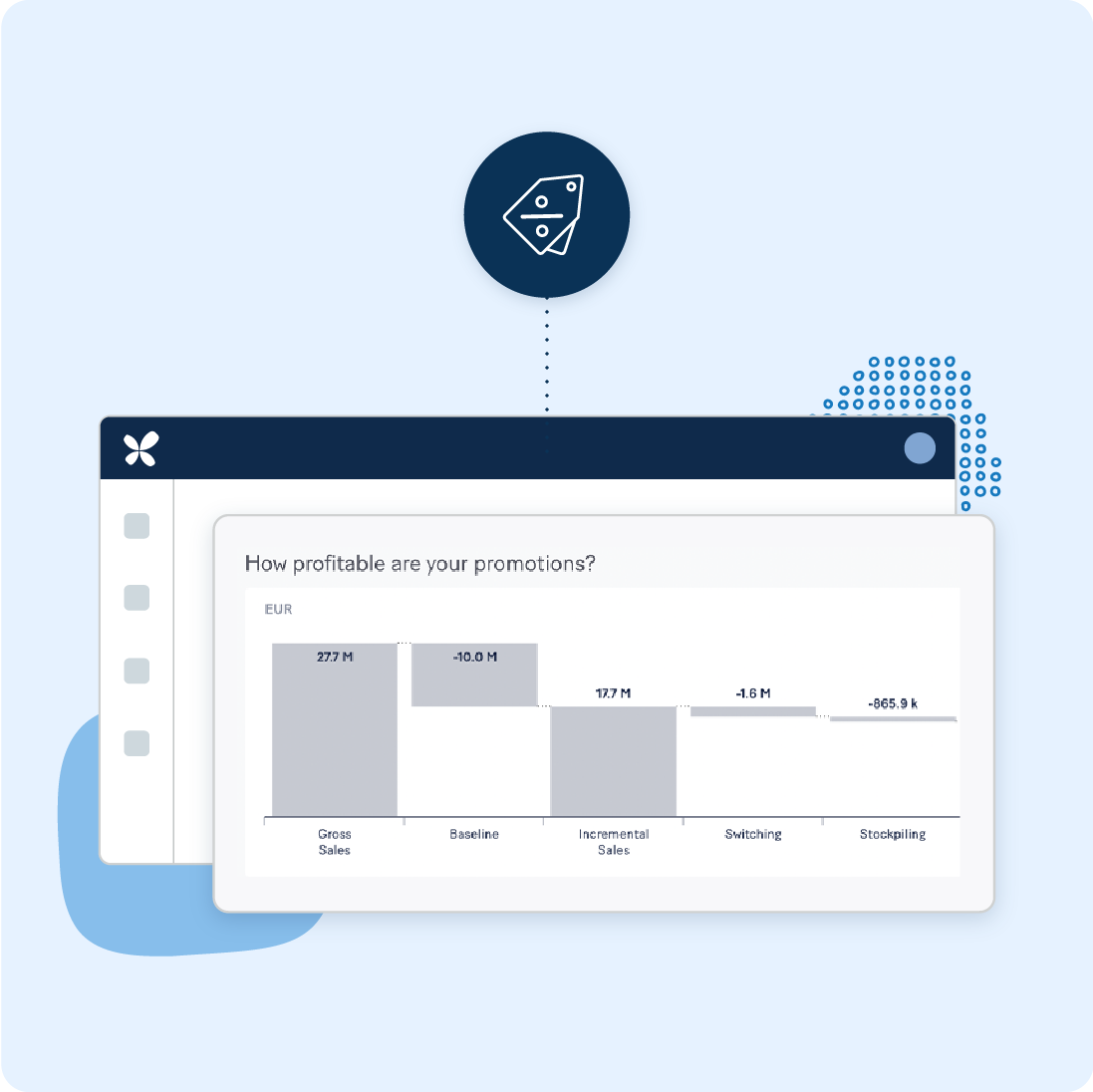
Automatically analyze all your past promotions, across every product and every store. Achieve savings by cutting promotions that don’t meet objectives.
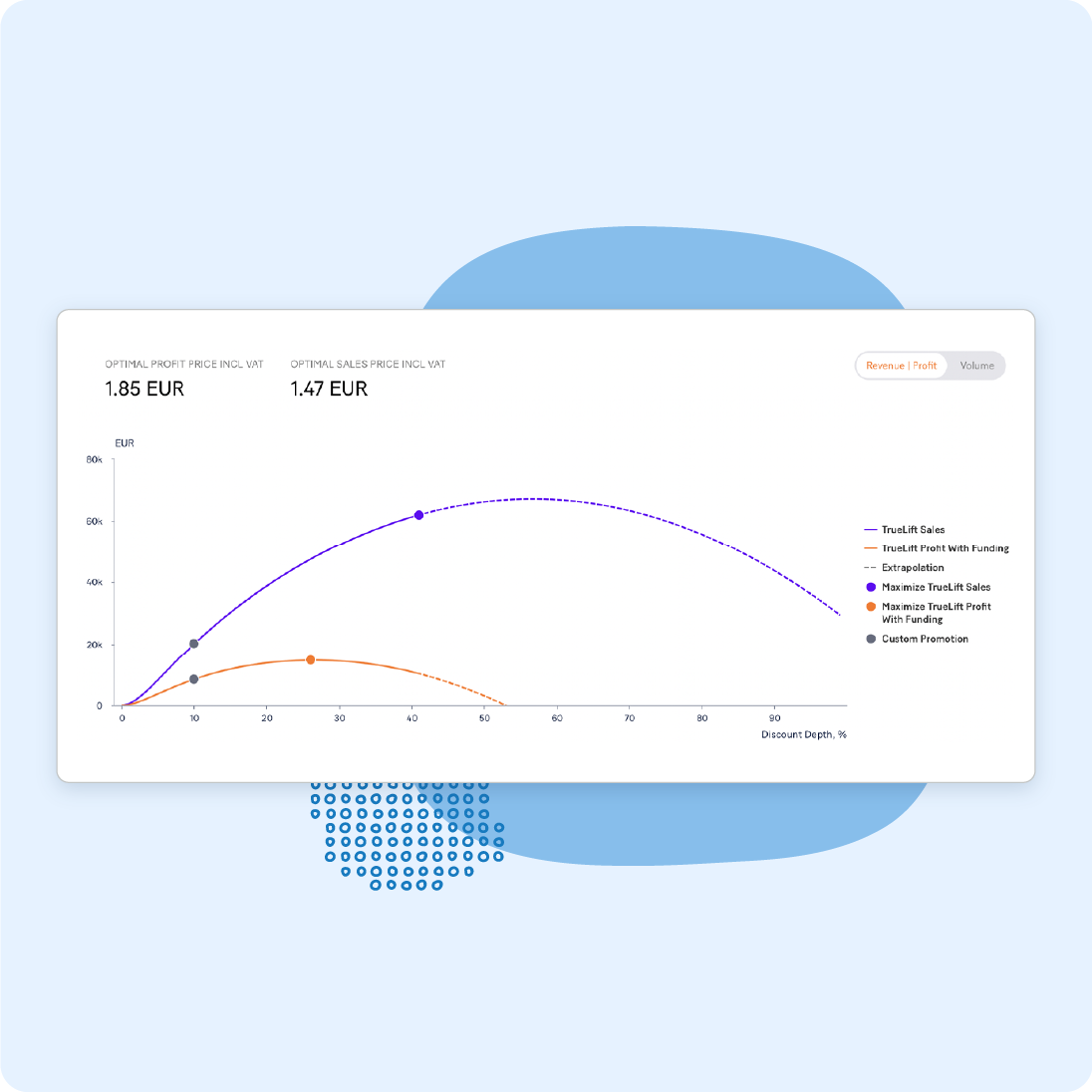
Test different campaign scenarios with an advanced simulation engine to determine which combination of price, mechanic, and display will drive the best results.
Plan all promotions in one tool, making it easier to share responsibilities, automate recurring manual processes, and maintain one source of truth.
Benefits
Improve promotional planning and execution with a cross-functional, AI-driven solution
Take advantage of our industry-leading forecast accuracy for promotional decisions. Evaluate past campaigns, plan new promotions, forecast impact, and meet your objectives, all within one collaborative tool.
Maximize your promotions returns
Automate and streamline the planning, evaluation, and execution of in-store and online campaigns. Optimize promotion outcomes: drive traffic, revenue, profit, and basket spend.

Automate processes and improve vendor collaboration
Collaborate, set targets, track performance, and get AI-driven recommendations. Utilize past campaigns data to support planned promotions, while improving collaboration with vendors, and secure more funding.

Understand the true impact of your promotions
Calculate baseline sales, quantify vendor funding, and account for switching, stockpiling, and halo effects to uncover your promotion’s true profit or loss value. Rapid deployment ensures quick results.

Test campaigns to predict impact
Simulate multiple scenarios in a sandbox-like environment to determine real-world impact. Take advantage of system-provided recommendations to improve outcomes and maximize revenue and profit.
Unify promotion and supply chain planning
Utilize our unified promotion planning software to coordinate promotion and supply chain planning, maximizing sales and preserving margins while reducing the potential for under- and overstocking.
Forecast with confidence
Take advantage of industry-leading forecast accuracy that allows you to make promotion decisions that align with your business objectives.
Automate processes and reduce errors
Collaborate, set targets, track performance, and react to external changes with our unified promotion planning software, which provides centralized data for more streamlined decisions.

Promotion planning & optimization
Promotions are one of the most valuable but least optimized areas of retail. In this demo video, we look at 5 key steps in promotion planning and how RELEX helps retailers run more effective promotion campaigns.

Resources you might be interested in
We’ve accumulated a wealth of supply chain & retail expertise from our 1,500+ planning specialists.

3 typical promotion challenges – and how to solve them
In this blog, our expert discusses three typical promotion challenges and provides some tips to help you avoid promotion pitfalls and avoid risking already tight margins.

5 ways to improve retail promotion strategy with planning technology
This blog discusses how having a promotional planning solution can help retailers maximize profit, effectively evaluate promotion campaigns, and reduce errors in the promotion planning process.

Case study: Mathem
Mathem, Sweden’s leading independent online grocery retailer, has achieved outstanding results in their promotion process and sales on promotion after implementing RELEX promotions planning.

Ready to transform your supply chain & retail planning?
We’re happy to discuss your business needs and share how our market-leading, unified platform can help you drive profitable growth across your sales and distribution channels.